{kind=link}
试图干翻所有 AI 公司,谷歌全家桶到底有多硬核?
2025 年,AI 越卷越狠,各家大模型你追我赶。进入 Gemini 时代的谷歌,在自家产品上的应用更是全面开花。
刚过去不久的 Google I/O 2025 开发者大会,不出所料,"AI" 依然是绝对主角。

去年,"AI" 一词在大会上被提及 120 次,今年也毫不逊色,被提及 92 次。
其中,"Gemini" 一词贯穿全场,高调亮相 95 次,频率还反超了 "AI",俨然成了谷歌新一代 AI 的代名词。
这次大会更新,让老狐眼前一亮,再次刷新了对 AI 潜力的认知:这才像谷歌,有老大哥的气魄。
作为谷歌主力的语言模型,Gemini 2.5 Pro 和 Gemini 2.5 Flash 自三月推出以来就保持高热度。
尤其 2.5 Pro,在 WebDev Arena 和 LMArena 等多个评测平台上,各个子任务几乎全线领先,属于实打实的 " 榜单霸主 "。
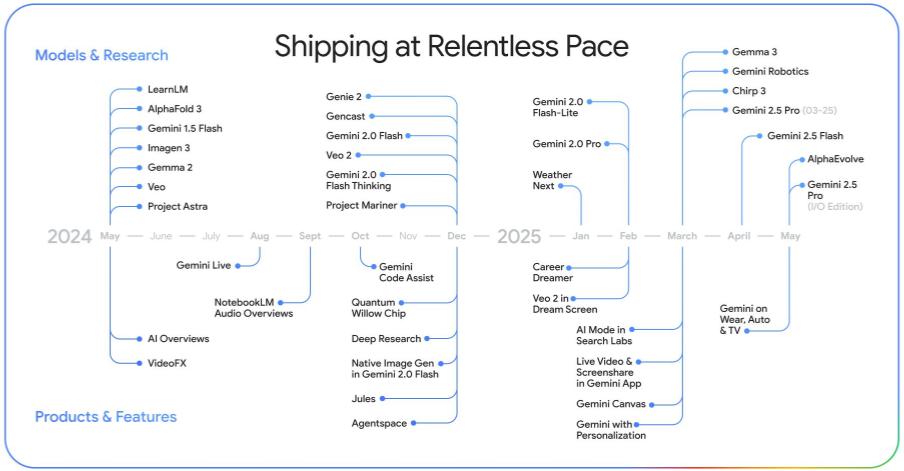
不过,谷歌并不满足于 " 够用 ",而是进一步强化 Buff:这次更新加入了全新的 Deep Think 模式。
当模型遇到更复杂的问题,Gemini 可以切换到 Deep Think 模式:它会 " 多想一会儿 ",牺牲一些响应时间,换取更准确的推理与回答。

这项机制让模型在作答前,就预先模拟多种可能的解法,推理路径更深、更稳。
按照谷歌公开的数据,Gemini 2.5 Pro 搭配 Deep Think 后,在数学、编程和多模态推理上的表现,甚至优于 OpenAI 的 o3。
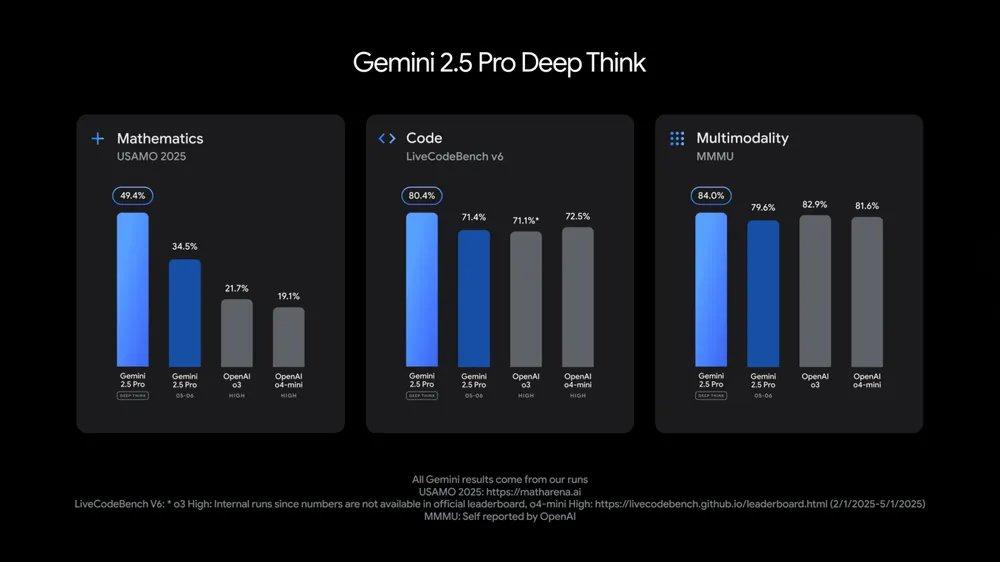
比如,它在 2025 年 USAMO 这类难度很高的数学测试中得分惊艳,也在编程比赛和多模态推理测试中表现出色。
不过,Deep Think 目前还在安全评估阶段,只向受信测试者开放。
Gemini 小将 Gemini 2.5 Flash 也迎来了升级,在推理、多模态、编程和长上下文等关键测试中都有提升,同时效率更高,谷歌评测显示其用 token 数量减少了 20% 到 30%。
全新的 2.5 Flash 版本已经在 Google AI Studio、Vertex AI 和 Gemini app 中开放预览体验。
有了强大模型做基础,谷歌开始在 Gemini 平台上玩出更多新花样。
Gemini 2.5 系列引入了不少新功能,最引人注意的是通过升级 Live API 实现的原生音频输出。
AI 不光会说话,声音还带感情,能听懂对话情绪,自动换语气,交流更自然。
感兴趣的狐友可以点击下方视频自行感受一下。
开发者可以直接用这套语音能力做出更自然的互动体验,而且还能调节语速、语调、口音,甚至模拟不同风格的说话方式。
与此同时,谷歌还上了多扬声器的文本转语音功能,能模拟两个人对话,支持 24 种语言,现在已经在 Gemini API 上能用了。
除了 " 能说 ",Gemini 现在也更 " 能干 " 了。
谷歌把原本只在实验项目里的 Project Mariner 加到了 Gemini API 和 Vertex AI 里,AI 可以一次做 10 件事,还能学会自动完成重复的任务。

为了方便开发者,Gemini 2.5 引入了 Thought Summaries 功能,能清晰展示模型的思考过程和调用细节。
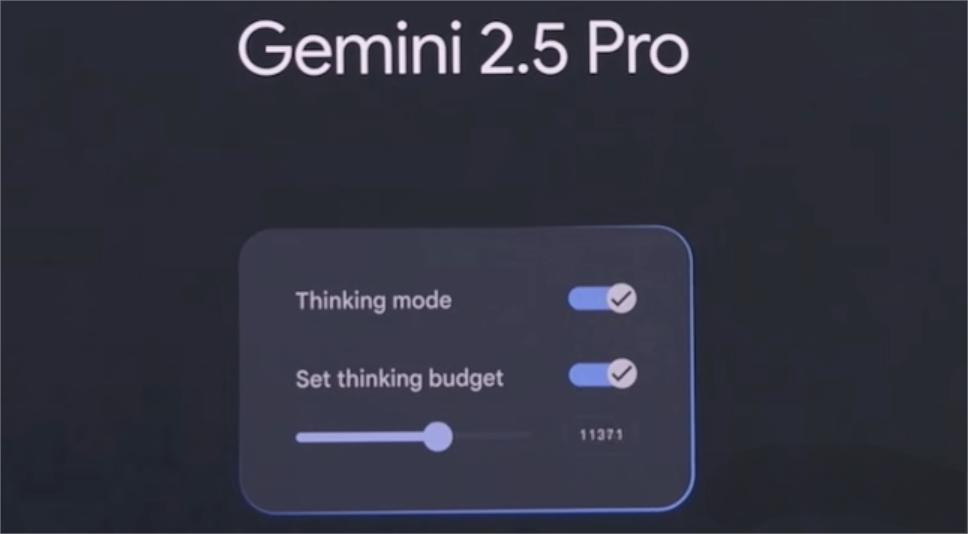
同时配备 Thinking Budgets,方便控制模型思考时使用的 token 数量,避免资源浪费。
Gemini SDK 也兼容 MCP 工具,方便与开源软件集成。
谷歌这波升级不止是做加法,还在试着改变游戏规则。
他们推出了一个新模型叫 Gemini Diffusion,完全不用 Transformer 架构,跑得更快,用起来更省。
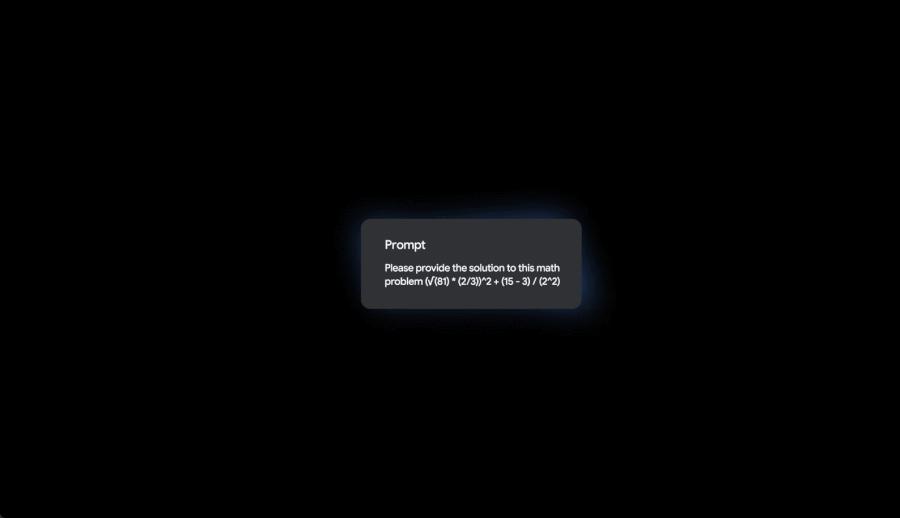
虽然目前表现刚和之前的 Flash-Lite 持平,但速度快了五倍。
Transformer 用了这么多年,算力又贵又慢,但苦于没啥替代手段,大家只能 " 将就着用 "。
如果这套扩散模型能继续打磨下去,说不定真能成为新的主流架构。

大模型之外,谷歌在多模态生成这块也疯狂上新,直接覆盖图像、视频、音频全赛道,真的是 " 全都要 "。
先说图像。最新上线的 Imagen 4,不仅细节超清晰,支持写实和抽象风,能做贺卡、海报,速度还比上一代快了 10 倍。

现在已经在 Gemini App、Whisk、Vertex AI 等多个平台上线。
图像有了,视频当然也不能缺。Veo 3 带来了原生 " 音画同步 " 生成,不光能做高质量视频,甚至连人物对白、背景音乐、环境音都能一起生成。

文本讲故事,几秒出片,连口型都能对上,像是开了电影拍摄外挂。
Veo 3 已向美国 Ultra 用户开放,企业用户也可通过 Vertex AI 使用。
音频方面,Lyria 2 同样不简单。现场演示的一段秘鲁风格舞曲节奏明快、旋律自然,完全听不出是 AI 做的,电吉他、鼓点、贝斯配合得一气呵成。
多个模型齐发还不够,谷歌还推出了电影制作工具 Flow,整合了 Imagen、Veo 和 Gemini 的能力。
只需用自然语言描述故事,还能导入角色素材,Flow 就能一键生成电影级的镜头,角色、场景还能跨镜头连续复用,创作流程更像是在 " 搭乐高 " 一样简单。

据介绍,美国 Google AI Pro 和 Ultra 用户可优先体验 Flow。
而在一边搞底层技术革新的同时,谷歌在 AI 落地应用上也可圈可点。
全新上线的 AI UI 设计工具 Google Stitch,老狐看完只想感叹一句:设计师的饭碗,又不稳了。
只需要用自然语言描述需求,它就能自动生成完整的网页或移动端界面,连 HTML/CSS 代码都能一起打包好,甚至一键导出到 Figma,直接接着做交互图和上线。
不像很多产品还卡在 " 排队申请内测 ",Stitch 是直接全量开放的,现在就能玩,地址在这儿 stitch.withgoogle.com
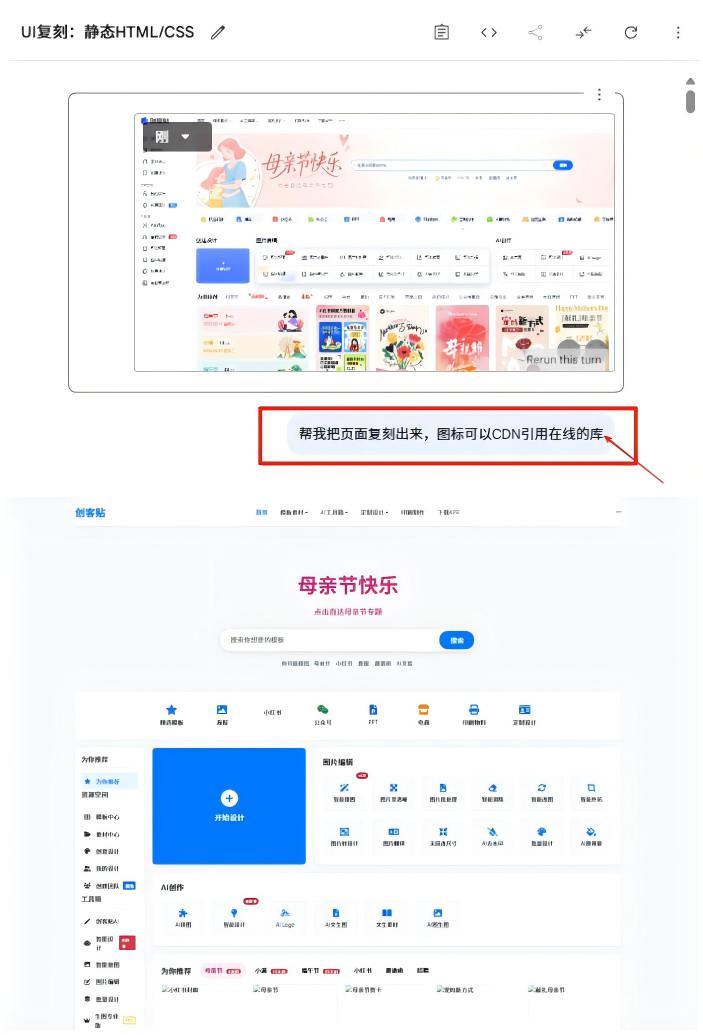
有网友拿创客贴首页随手截了张图,丢进去随口打了句 " 还原页面 ",几秒钟后,AI 不仅给出了 HTML 文件,跑起来后还原度居然高得离谱。
其实这种风格的产品更新,在谷歌今年的布局里并不少见。
很多人原以为,AI 会把传统搜索打废,但谷歌的做法恰恰相反:它干脆把搜索重做了一遍。
这次在美国先上线的全新 AI Mode,就是一个结合多模态和推理能力的搜索新形态。
这不是简单在原有引擎上加个大模型接口,而是基于 Gemini 2.5,重构了整个搜索逻辑。
它背后采用的是一套叫 query fan-out 的技术,简单来说就是能自动把你提的问题拆解成多个子任务,再同时搜索、整合信息。
谷歌还提前预告了 AI Mode 的几项重磅功能:
比如 Deep Search,AI 会自己发起上百次搜索,生成带引用的深度报告。
Search Live 支持实景互动,你对着镜头提问,它能看图识物并语音回答。
还有 " 帮我买票 " 这种 Agent 功能,能自动跨平台比价、下单。
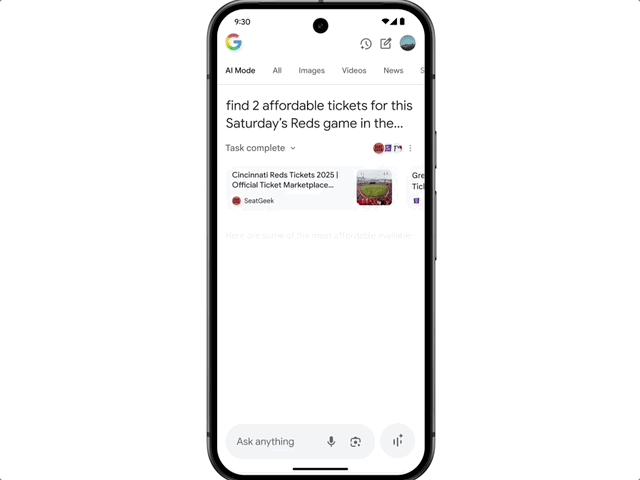
除了查信息、买门票,这波升级对购物体验也进行了全面改造。
新的 AI Mode 把 Gemini 的智能能力和 Google 的购物知识图谱结合,整合了 500 亿 + 商品信息。
用户只需要告诉它预算、颜色、尺寸,它就能快速帮你筛选、比价、下单。

最后,至于大家关心的价格,Google 这次也端出了 " 大杯 " 和 " 超大杯 " 套餐:AI Pro 和 AI Ultra,顶配 Ultra 直接开价 249 美元 / 月。

听起来不便宜,但服务确实顶:几乎不限量的使用额度,加上 30TB 的 Google Cloud 云存储,性价比对得起这个价,尤其是对那种靠 AI 吃饭、挣美元花美元的用户来说,比很多国内会员都值。
不过谷歌也清楚,这年头用户忠诚度稀缺,隔壁 Perplexity、OpenAI、微软天天虎视眈眈,不追着更新点杀手锏,用户分分钟 " 人走茶凉 "。
好在谷歌一直都知道,自己最大底牌就是那些用户天天离不开的工具。AI 用得再花哨,最后还得回到搜索、Gmail、Docs 这些刚需里来。
谷歌干脆一句话:你最常用的,全都给你装上 AI。
参考资料:差评、量子位、机器之心、谷歌等其他网络截图编辑:不吃麦芽糖