{kind=link}
4 分钟新闻联播力挺,时空壶 AI 耳机爆火不是没道理
不少做外贸的朋友常常要和海外客户沟通,翻译耳机成了日常 " 标配 "。
不过,传统同传耳机经常是 " 一人一句 " 式的翻译,听起来很生硬,像是在机械地对话,更别提两个人同时说话时,耳机还经常把声音搞混,翻译错漏不断,体验真心不好。
最近,狐妹发现时空壶这个品牌的同传耳机越来越火,原因正是它解决了 " 多声音叠加 " 这个难题。

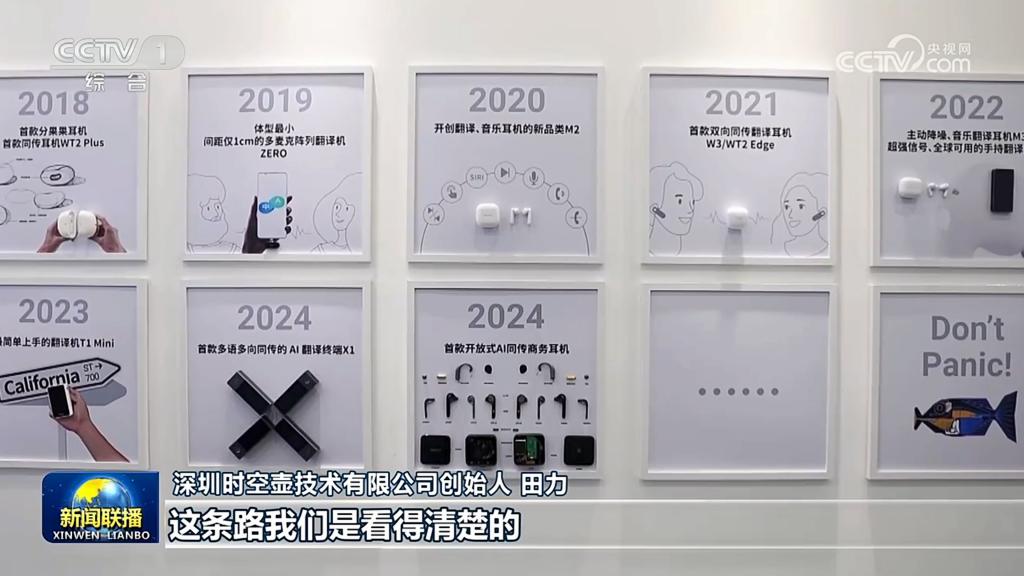
甚至前阵子,央视 30 分钟的《新闻联播》还花了整整 4 分钟专门报道他们,足见其实力。

这种 " 能打 " 的背后,是时空壶埋头多年打磨的矢量降噪技术,让耳机在嘈杂环境中也能准确 " 听清楚 ";再加上 AI 大模型支撑翻译逻辑,确保 " 翻得准 "。
听得准、翻得好,直接拉高了 AI 同传的技术门槛。
不管是在地铁、机场还是国际展会,这些最考验设备的场景里,它都能清晰捕捉人声、快速翻译输出,不卡壳、不跑偏,真正做到 " 听得清、翻得顺 "。

时空壶正在把 "AI 同传 " 这件听起来很高阶的技术,悄悄做进了日常里。让每个人,在交流中都能拥有自己的 " 贾维斯 "。
AI 同传最难不是 " 翻译 ",而是 " 听不清 "
说起 AI 翻译,很多人第一反应可能是翻译准确率问题,实际上在工程和算法团队眼中,最难啃的一块骨头却是语音输入端的噪声干扰。

特别是在机场广播声不断、地铁轰鸣嘈杂、展会人流如织的环境中,很多翻译耳机要么 " 听不清 " 说话内容,要么将背景音混进翻译中,把无关声音当成主语音来识别,轻则卡顿重则词不达意。
打个比方,这就像让一个厨师炒菜,但你给他的食材是模糊不清的原料,甚至夹杂了别的东西炒出来的菜能对味就奇怪了。翻译系统也是一样,如果语音信号不干净,哪怕再先进的大模型也无法准确还原原意。
技术的第一步,不是 " 翻得像母语 ",而是 " 收得够干净 "。如果收音源头出错,后面的大模型再强也 " 巧妇难为无米之炊 "。
嘈杂环境下如何听 " 对 " 声音?
在展会、机场、地铁这类高噪音环境中,如何让翻译耳机 " 听得清 "?更进一步是:如何让它只听你的声音?这正是时空壶率先攻克的关键难题:矢量降噪技术。

传统降噪耳机的做法往往是 " 压背景音 ",通过消音、降音来对抗环境嘈杂。但这类方法在多声源、复杂回响的场景中仍显力不从心。因为它们压根分不清,哪个声音才是你要说的。
而时空壶的矢量降噪,换了个思路。它不是 " 消音 ",而是 " 识人 ":通过三麦克风阵列配合空间算法,给每段声音 " 定位打标 ",精准锁定主说话人声音的方向和距离,只接收该方向的语音信号,并实时屏蔽掉其他干扰音。

举个例子:你在展会上和法国客户交谈,周围是中文聊天、背景播报和来来往往的脚步声。普通耳机会 " 懵圈 ",无法分辨该听谁的。而时空壶能聪明地判断出你是 " 主说话人 ",只采集你的声音,把其他全都自动降噪处理。
更妙的是,在中英双向交流中,矢量降噪还能智能 " 划分角色 ":只录入本方说话人的语音,不会被对方耳机的声音反串干扰。这就像对话双方各配了一位专属翻译,各自只为 " 雇主 " 服务,绝不串台。

从技术角度看,这项突破并非锦上添花,而是双向同传能否正常运行的基础。若没有 " 听得准 ",翻得再快也只是 " 错误高速输出 "。
所以,狐妹觉得时空壶真正惊艳的地方,不是它翻得多快、声音多自然,而是它让机器第一次具备了 " 选择性听力:在人声鼎沸中,耳机只听你一个人说话,像贴身的 AI 翻译助手,不跑偏、不打岔、不出戏。
" 听懂了 " 还不够,大模型助力 " 翻得准 "
把声音听清楚,只是 AI 翻译的第一步。
很多人用过传统翻译软件,应该都有类似的感受:翻译出来的句子虽然每个词都没错,但听起来总觉得别扭,不是我们平时说话的方式。问题就出在 " 只翻字,不翻意思 "。
语言从来不是简单的词对词转换。一句话放在不同语境下,意思可能完全不同;说话人的语气、说话的速度,甚至前后聊天内容的关联,都会影响真正想表达的意思。
时空壶解决了 " 听 " 的问题之后,还在 " 翻 " 的体验上往前迈了一大步。

时空壶内置的 AI 大模型不再是逐词对应,而是像母语者一样,先理解你话中的语义、意图和语境,再用最自然、贴切的方式重新表达。
它能自动关联对话的上下文,准确判断歧义词的含义,还会根据说话人的语速和语气调整翻译节奏,让对话不再像冷冰冰的 " 翻译 "。
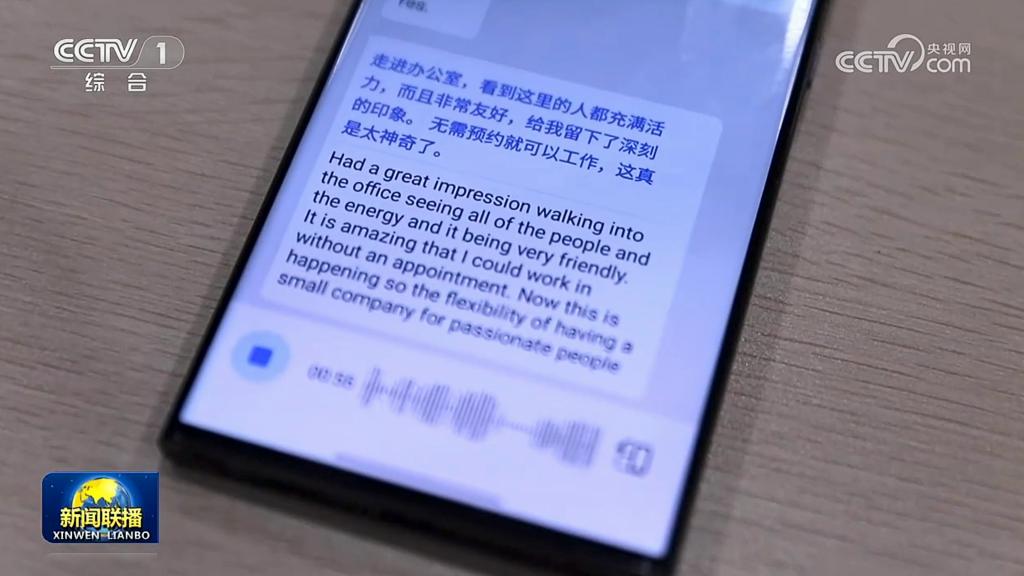
举个例子:在一次商务电话会议中,客户用英文说了句 "Let ’ s table this for now",传统翻译可能直译成 " 现在让我们把这个桌子摆好 ",让人摸不着头脑。
但时空壶的大模型结合上下文,明白这句话是 " 我们先暂时搁置这个议题 " 的意思,翻译成中文时就会自然表达出正确的含义。这样,沟通更顺畅,也避免了误解。

这种 " 再表达 " 的能力,得益于多模态 AI、自然语言理解和上下文建模等先进技术的融合,让语言模型从 " 词的组合 " 跃升为 " 意义的传递 "。
这种感觉很微妙。不少用过的人常会说:" 它不像是死板地翻译,而像是理解了之后再说出来。"
从实验室到日常:时空壶把 L3 同传变成了现实
过去,说起 AI 同声传译,很多人第一反应还是 " 实验室里的黑科技 "。技术虽新,但体验断层、应用门槛高,离我们真实生活还有不小距离。
但这几年变化很快。早在 2021 年,时空壶就率先推出业内首创的 " 矢量降噪 " 架构:它不只是 " 降噪 ",而是能精准锁定主说话人,在地铁、机场、展会这种人声鼎沸的环境里,也能清晰捕捉你的声音,实现 " 听得清 " 的关键突破。

听清了,还得 " 翻得准 "。这就进入更高难度:机器不仅要听懂字面意思,还要理解上下文、口语习惯、甚至文化背景。
为了解决这类问题,时空壶一边迭代翻译模型,一边推动行业标准——他们参与建立了一套类似自动驾驶的 "AI 同传能力分级体系 "。

从最初的 L1(仅能文本翻译)、L2(能语音播报但延迟较大),到如今的 L3 级,时空壶已实现 " 基本语音同传 ":延迟控制在 5 秒以内,支持多语言、多角色双向对话,且能处理地道表达,让翻译听起来更自然、不 " 翻车 "。

目前,时空壶的耳机已可在嘈杂场所稳定运行,还能对接线上会议系统,实现远程同传。商务出行、跨国会议、出境旅行,甚至语言学习,使用场景都在快速拓宽。AI 同传,正在从 " 能用 " 迈向 " 好用 "。

当然,他们的目标还不止于此。下一个挑战,是迈向 L4 阶段,翻译像真人一样自然,甚至能识别说话人的情绪和语气,调整表达风格,让机器像贴身口译员一样 " 察言观色 "。为此,时空壶团队正研发多场景上下文识别、情绪语音合成、方言和口音适配等关键能力。
可以说,时空壶正在走进 AI 翻译领域的 " 无人区 "。这条路不容易,但也正因为他们的坚持和深耕,才有了今天这款越来越多人在用,连《新闻联播》都深度报道的 " 宝藏产品 "。
技术落地,最大的浪漫,就是把复杂的事情,做成让人几乎忘了它有多复杂。时空壶,正在把 " AI 同传 " 这件事,变得像日常交流一样自然。