{kind=link}
多模态模型具备“物理推理能力”了吗?新基准揭示:表现最好的GPT-o4 mini也远不及人类!
表现最好的 GPT-o4 mini,物理推理能力也远不及人类!
就在最近,来自香港大学、密歇根大学等机构的研究人员补齐了现有评估体系中的一处关键空白——
评估多模态模型是否具备 " 物理推理能力 "。

物理推理,即模型在面对真实或拟真的物理情境时,能否综合利用视觉信息、物理常识、数学建模进行判断和预测,被认为是通向具身智能的关键能力。
但这一能力在现有评估体系中仍是空白。
对此,研究人员构建了PhyX(Physical Reasoning Benchmark),首个专门面向多模态大模型物理推理能力的大规模基准测试。
PhyX 包含 3000 道题目,涵盖 6 大物理学科(力学、电磁、热学、光学、波动、现代物理),25 个细分子类与 6 类推理方式(如空间理解、物理建模、公式联立、预测性推理等),每道题目都结合教材级图像与真实物理设定,并由 STEM 专业研究生精心审核。
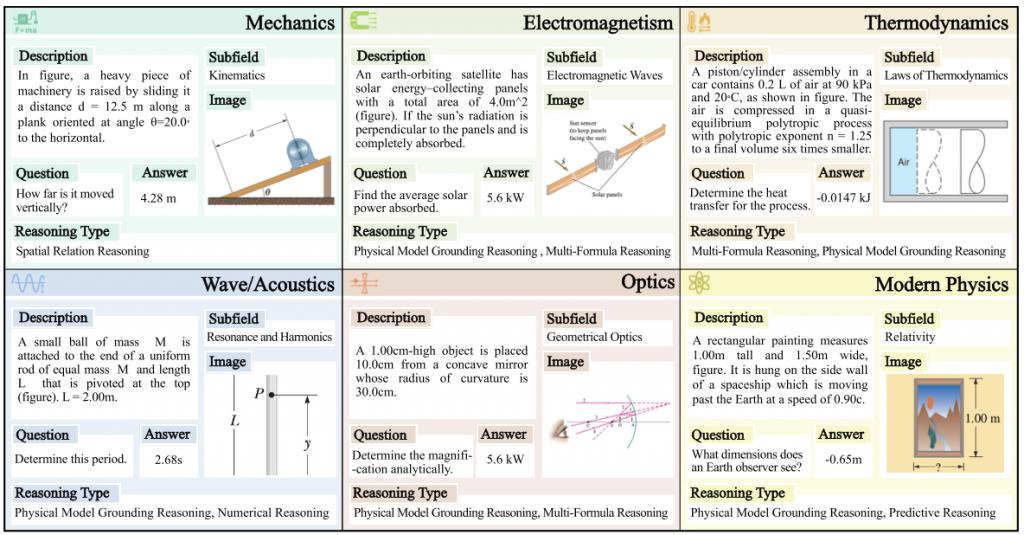
那么,各大主流模型在 PhyX 上的表现如何呢?
强如 GPT-o4 mini 也比不上人类
截止目前,多模态大语言模型(MLLMs)不断刷新各类图文推理与科学问答任务的记录。
诸如 GPT-4o、Claude3.7、DeepSeek 系列等最新模型,已经在数学奥赛(AIME、MATH-V)、通识科学(MMMU)、跨学科推理(OlympiadBench)等标准化测试中展现出堪比人类的表现。
然而,这些测试所衡量的往往是抽象计算能力、公式记忆与文本逻辑,尚未系统性地检验模型能否真正理解现实世界中的物理规律与视觉场景。
利用 PhyX,研究人员在包括 GPT-4o、Claude3.7、DeepSeek-R 等在内的16 个主流模型上进行了系统评估,发现:
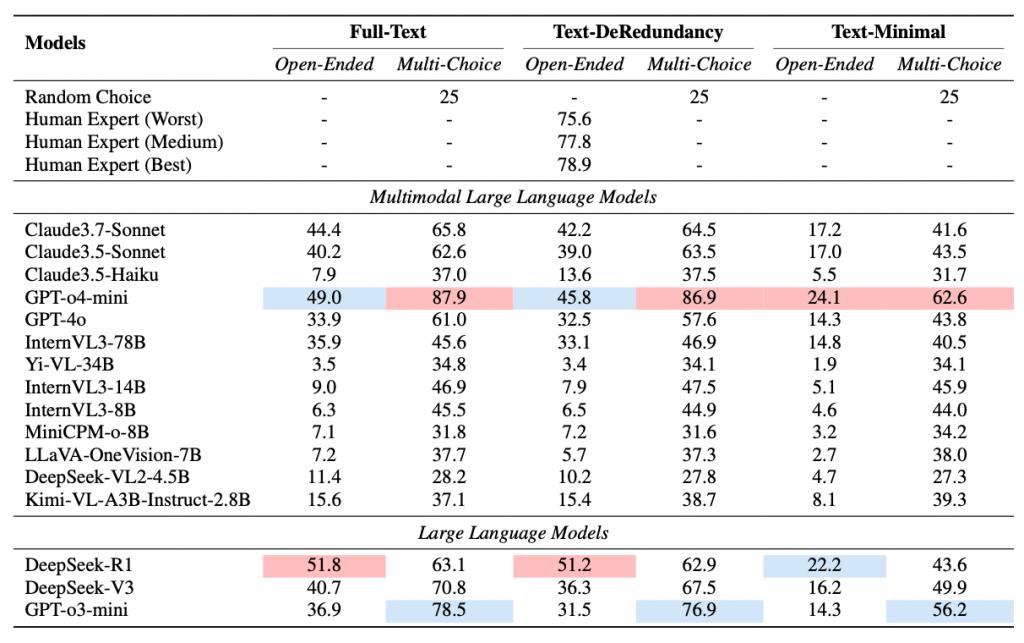
即便是表现最好的模型 GPT-o4 mini,其准确率也仅为 45.8%,而人类物理本科 / 研究生在同一任务上的准确率达 75.6%;
在现代物理、电磁学、热力学等高阶推理任务上,模型的表现尤其低下,准确率不足 30%;
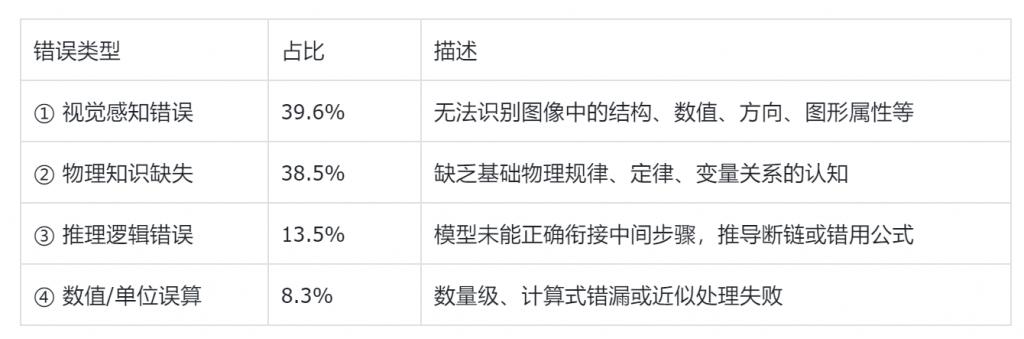
错误分析显示,超过三分之一错误来自图像感知失败,其次是知识缺失与逻辑推理能力不足。
说完结果,我们顺便展开一下 PhyX 的构建过程。
PhyX 目标在于建立一个真实、多样、具挑战性的物理图文推理测试环,系统评估多模态模型在处理物理场景中是否具备与人类相当的 " 物理常识、感知理解与符号建模 " 能力。
与现有多模态基准(如 VQA、ScienceQA)侧重日常知识与科普推理不同,PhyX 聚焦高层次的物理专业问题解决能力,强调图文信息的深度结合、推理链条的完整性与真实感知与建模的还原度。
学科维度与题目覆盖
它总计包含3000 道图文物理题目,内容涵盖大学物理主干课程的六大核心学科:
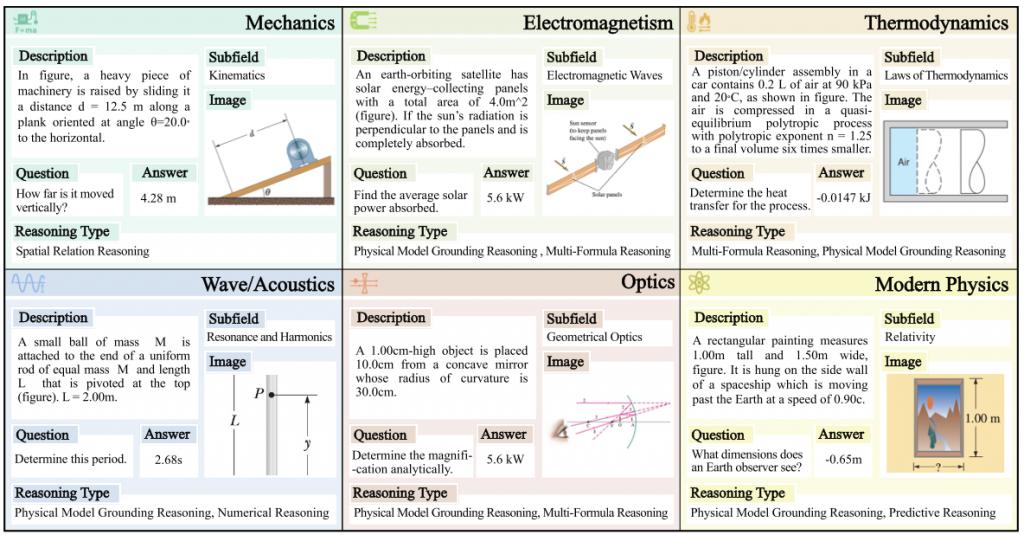
每道题均为图文结合问题,包含插图、图表或场景图,并匹配相应文字说明与问题设定。
下图给出了每个学科的一个 PhyX 样本。
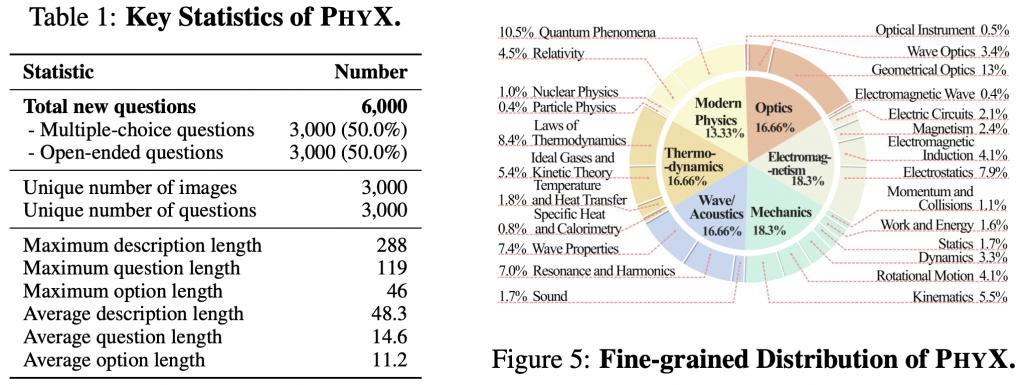
此外,还详细给出了所覆盖的科目及相关统计数据,六大物理学科分布均匀。
左边对 PhyX 的关键数据进行了描述性统计。如表 1 所示,PhyX 中共有 6000 个问题,开放性问题与多选题各 3000 个。
PhyX 的优越性
为细粒度分析模型能力,PhyX 对每道题标注了 0~2 种核心推理类型,共六类。
该标签体系有助于研究者系统性研究模型在哪些类型推理上表现良好或薄弱,并支持跨模型、跨模态、跨学科横向比较。

PhyX 为每道题提供三种输入模态与两类题型,以支持多种模型与能力维度的测试:

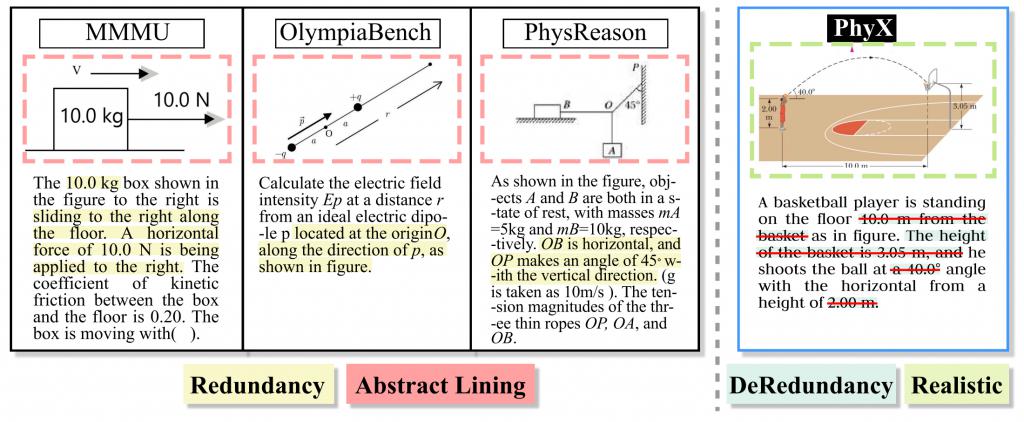
下图展示了 PhyX 如何去除重复内容:
每道题支持两种格式切换,适应不同类型模型(闭式 vs 开放式、判别 vs 生成):
多项选择题(MC):方便统一评分与大规模测试
主观问答题(OE):用于评估链式推理、生成能力与公式表达
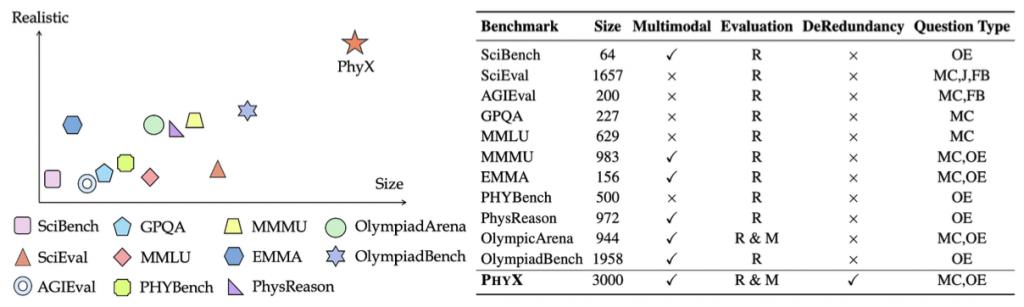
下图与下表给出了 PhyX 与已有基准的差异,可见 PhyX 全面领先于现有基准。
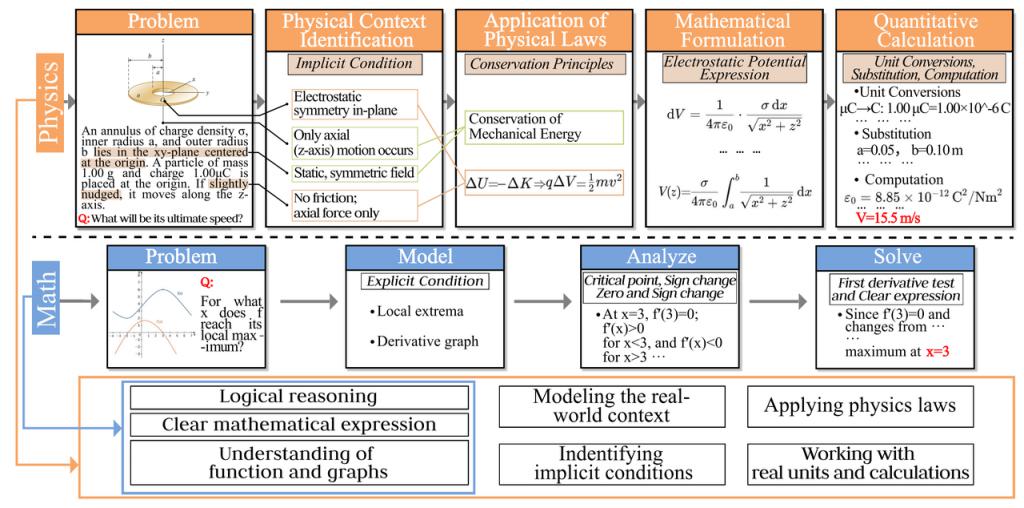
下图为基于 GPT-4o 的推理轨迹真实示例及所需时间对比解决物理和数学问题的能力。
数据构建与审核流程
为确保题目质量与广度,PhyX 采用如下多轮数据构建流程:
1、初始设计与题源采集题目来源包括:物理教材、考试题库、公开课程材料、大学教案与题目设计所有题目要求结合图像;
2、专业标注者构建与重写组建跨高校研究生团队(物理、AI 双背景),每位标注者负责 " 构建 + 重写 + 图文匹配 " 任务图像统一制作规范,确保风格多样但信息清晰;
3、质量控制与审核每题需经过双人交叉验证:科学性 + 语言可读性标注项包括:学科标签、推理类型、题型双版本、答案及解析自动检测图文重复性 + 模板重合度 + 图像内容覆盖度。
模型评估与测试结果
为了全面评估当前多模态大模型(MLLM)与语言模型(LLM)在真实物理场景下的理解与推理能力,研究人员在 PhyX-testmini 子集(共 1,000 道题)上对 16 种主流模型进行了系统性测试。
该子集覆盖所有学科与推理类型,采用统一输入模态和答题格式,确保评估公平与可复现。
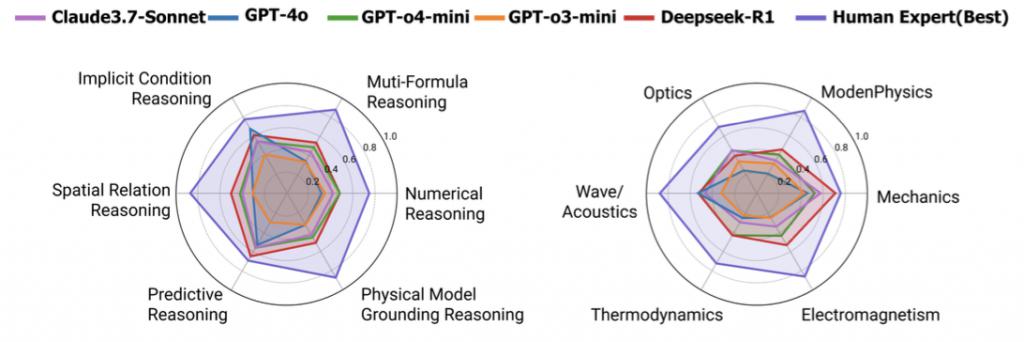
下图为三种领先的 MLLM、两种领先的 LLM 在 PhyX 基准中的正确率。
所有模型均在 zero-shot(零样本)设定下运行,即不提供任何示例或任务微调,以真实反映其物理常识迁移能力与场景泛化能力。
即使是表现最好的模型(如 GPT-o4 mini 或 DeepSeek-R1),也远未达到人类水平,尤其在 " 具图像感知 + 多步建模 " 的综合任务中显著失分。
下表给出了在 PhyX 基准上不同 LLM 和 MLLM 的结果比较。PHYX 的 testmini 子集的准确度分数。每个模型中得分最高的部分和总体最高分分别以蓝色和红色突出显示。
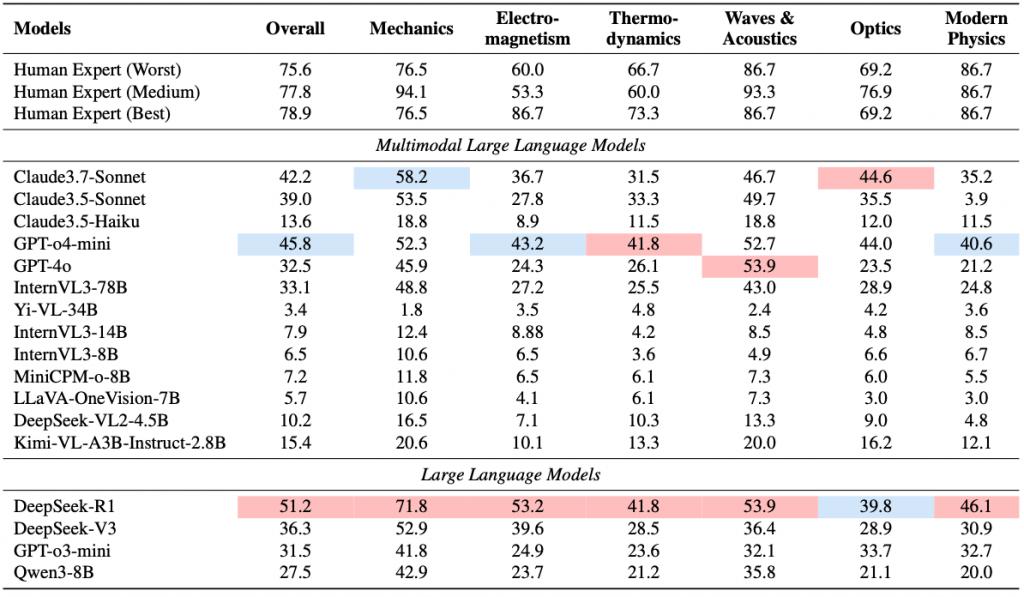
研究人员进一步对模型在六大学科维度的得分情况做了细分分析。
下表显示了,不同物理学领域的模型平均得分(开放式文本)冗余问题。各部分模型最高分及总最高分分别以蓝色和红色突出显示:
GPT-4o 在 " 现代物理 " 类题目的表现仅为 21.2%,远低于人类平均;
所有模型在 " 电磁学、热力学 " 题型中的准确率均低于 50%;
" 力学、波动声学 " 中模型表现略优,但差距仍在 20 分以上。
模型错误分析与能力瓶颈
尽管多模态大模型在通用图文问答与常识性推理上表现强劲,但在 PhyX 上,它们的错误却暴露出更深层次的结构性缺陷。
研究人员对 GPT-4o 在 testmini 子集上的 100+ 个错误样本进行了逐题分析与专家标注,总结出如下主要问题类别及其占比见下图:

在错误分析中,研究人员观察到 MLLM(特别是 GPT-4o)倾向于:
过度依赖文字提示:一旦图像中的信息未在题干中明示,模型倾向忽略;
图像信息降权处理:哪怕图像中有明确变量、结构或数值,模型也更偏好使用题干描述;
多模态融合机制缺乏推理引导:未能主动调取图像细节来修正文字中的不确定性或模糊性。
这表明,现有 MLLM" 多模态理解 " 仍更接近于图文匹配或粗粒特征拼接,缺乏具备 " 物理结构建模意图 " 的跨模态融合能力。
更多细节欢迎查阅原论文。
Project Page: https://phyx-bench.github.io/
Arxiv: https://arxiv.org/abs/2505.15929
Github: https://github.com/NastyMarcus/PhyX
Huggingface Dataset: https://huggingface.co/datasets/Cloudriver/PhyX
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
点亮星标
科技前沿进展每日见